The Playbook for AI Value Creation
Four years of measuring adoption has produced a generation of organizations that track everything and know nothing about what it produced. Here's what the organizations closing the gap are actually doing differently.

- ● 97% of enterprises deployed AI agents. 29% report significant ROI. The gap is a leadership and measurement failure, not a technology failure.
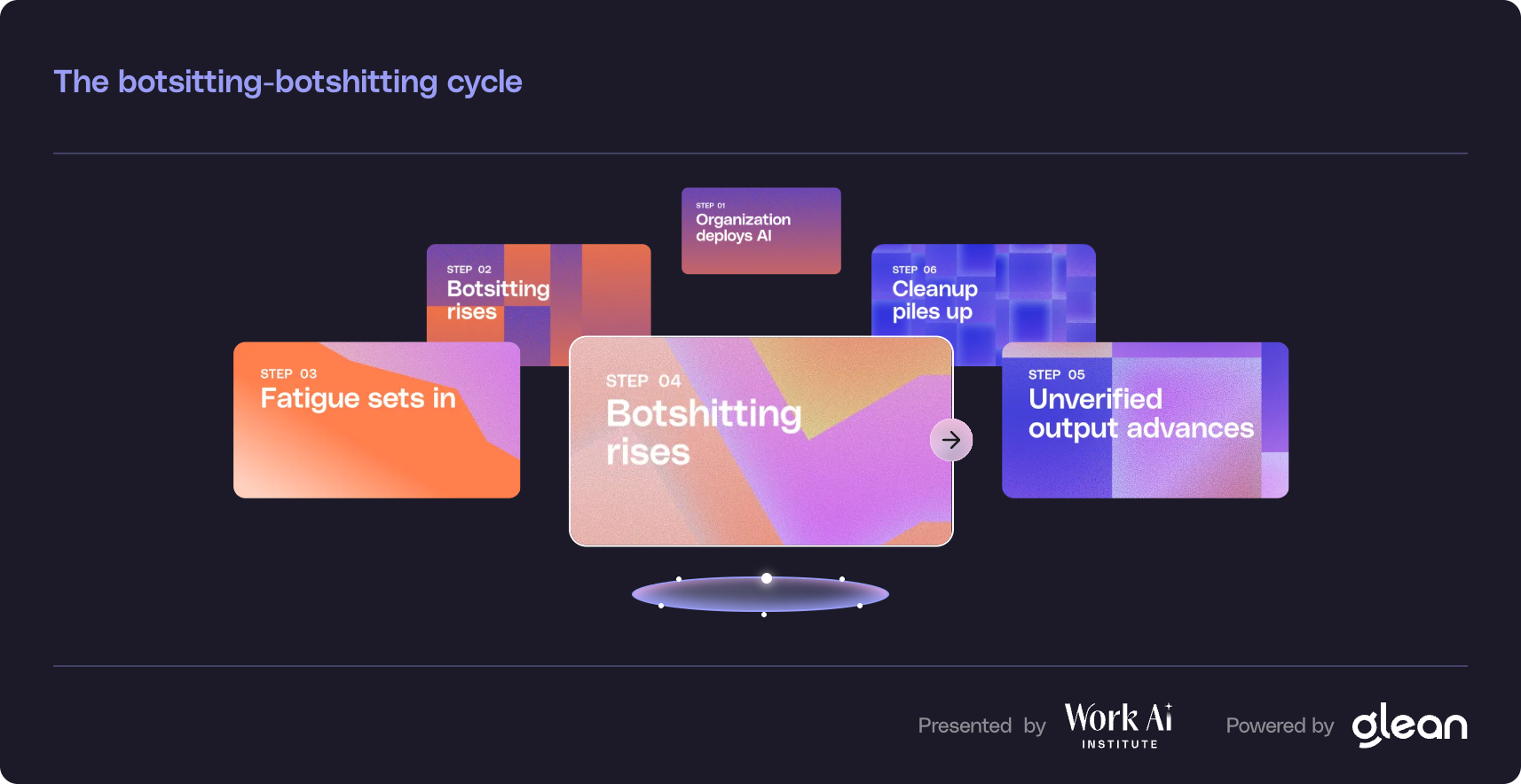
- ● Botsitting — more time supervising AI than gaining from it — is the dominant knowledge worker experience in 2026, not the exception.
- ● Token consumption grew ~320x per org in 12 months while value stayed flat. The spend and the outcomes are now visibly decoupled.
- ● The organizations closing the gap have documented workflows, explicit quality criteria, and measurement tied to business outcomes.
- ● Three 2027 shifts — model sovereignty, token optimization, autonomous loops — are arriving. Most programs are not prepared for any of them.
97% of C-suite leaders deployed AI agents in the past twelve months. 29% reported significant ROI.
The people tracking AI adoption saw the 97% and called it a win. The people responsible for results are looking at the 29% and running out of time to explain the gap.
Here is what that gap is made of, why it will not close on its own, and what the organizations closing it are actually doing differently.
Key findings for AI enablement leaders:
- The 68-point gap between AI deployment (97%) and significant ROI (29%) is a leadership and measurement failure, not a technology failure
- Botsitting — more time supervising AI than gaining from it — is the dominant knowledge worker experience in 2026, not the exception
- Token consumption per organization grew ~320x in twelve months while value stayed flat; the spend and the outcomes are now visibly decoupled
- The organizations closing the gap have documented workflows, explicit quality criteria, and measurement tied to business outcomes — none of which correlate with seat count
- Non-technical leaders are the differentiator for what comes next — the constraint is no longer model quality, it is orchestration and response quality
Why Enterprise AI Adoption Fails to Produce ROI
Four years of measuring seats and tokens has produced something specific: organizations that can tell you exactly how much AI they are using and almost nothing about what it produced.
The Data Is Telling a Different Story
Deployment is measurable. Value requires defining what good looks like before you can know whether you achieved it — and most organizations skipped that step. They tracked what was trackable — usage rates, seat counts, token consumption. Glean's 2026 Work AI Index has a word for what most knowledge workers are actually experiencing inside those numbers: botsitting. More time supervising AI, correcting AI, redirecting AI than doing the work the AI was supposed to handle. Section's biannual proficiency survey found that 67% of workers use AI weekly. 5.5% are proficient enough to generate consistent value. Writer's survey of 2,400 global workers and leaders put the deployment-to-ROI gap at 68 points — the widest in enterprise AI history. And the value that is being created is concentrating at the top 10% of earners while the majority may be gaining nothing at all.
The adoption numbers are real. The value has not followed.
The people who ran those adoption programs built the infrastructure they were asked to build. But the infrastructure was designed to measure the wrong thing, and now the CFO is looking at a line item that has grown by an order of magnitude without a matching return. That conversation is already happening in most organizations. It does not end well for the people who cannot answer it with evidence.
The Botsitting Problem
The botsitting pattern shows up most clearly in mandated enterprise rollouts. When knowledge workers have access to both Microsoft Copilot and ChatGPT, 76% choose ChatGPT — not because Copilot is worse on every dimension, but because adoption mandated without genuine workflow fit produces exactly this behavior. Usage climbs. Satisfaction and value do not.
The Hidden Financial Liability
What most AI enablement leaders have not named yet is the financial liability sitting inside their programs. OpenAI's State of Enterprise AI 2025 found that reasoning token consumption per organization grew roughly 320 times in twelve months. Databricks found that organizations deployed more than 1,000% more AI models into production year over year. Gartner forecasts that 40% of agentic AI projects will fail — and the actual rate may be higher. The cost of model calls is growing faster than the value they create, half-built agents are floating in production, vibe-coded experiments are multiplying the security surface, and a productive minority of users is pulling the average up while the majority figures out what they are supposed to do. The CFO cannot see the difference between the top 5% and the other 95% on the same budget line. When the question arrives, the program either has evidence or it doesn't.
The organizations that survive this build a direct translation between AI activity and the numbers finance already tracks — revenue protected, cost reduced, time reclaimed in terms that map to headcount or margin. Building that translation is what shifts the conversation from "prove it" to "scale it."
What AI-Native Actually Means
Everyone is talking about becoming an AI-native organization. Most of what gets written about it is either moonshot theory or nothing at all. We compared Airbnb and Meta's opposing approaches to AI-native organization design — the contrast shows more about the real strategic choices available than most frameworks published on the topic.
The Moonshot: Fin's $3.6B Exit
The moonshot version is Fin — formerly Intercom. Salesforce agreed to acquire them for $3.6 billion earlier this month. Fin built a dominant position in AI customer service by making a deliberate bet on a single use case at the intersection of what large language models are genuinely good at and what Fin had deep operational knowledge in, then documented the workflows, built the evaluation criteria, and ran real experiments over real cycles until the model was handling tier-one support better than most human teams could. Studying that outcome without understanding the conditions that made it possible produces the wrong lessons. The specific stack of advantages Fin brought — years of customer interaction data, deep workflow knowledge, a business model that made the bet rational — is not something most organizations can import.
For Mid-Sized Organizations
For a mid-sized technology business, AI-native looks different. Set operational and customer goals first, before touching the tools. Align training, incentives, and documentation around those goals. Document the workflows that happen most frequently and slow the most people down, and systematically reduce the friction in them. Map the distance between your teams and your customers, and use AI to close it. Take stock of the competitive assets you actually hold — customer data, distribution, domain expertise, relationships — and make calculated bets from those real strengths. Every AI decision that is not anchored to a real competitive asset is an experiment. Some experiments are worth running. Most should not be in the budget.
For Agencies, It's a Harder Reset
For an agency, AI-native is a harder conversation. AI does not make agencies more efficient at the margin — it erodes the margins themselves. The agencies that survive are not the ones that adopted AI fastest. They are the ones that were clear enough about what they actually provide — judgment, taste, client trust, domain expertise — to redesign their operating model around the parts AI cannot replicate. The organizations that answered "what do clients pay us for that AI cannot do" before deploying their tools are in a fundamentally different position than the ones that started deploying and hoped the answer would appear.
The Foundation That Applies at Every Scale
What all three of these look like at the foundation: documented workflows, explicit evaluation criteria, baseline measurement tied to business outcomes. The bet changes by scale and context. The foundation does not.
The most common reason organizations cannot make a calculated bet is that they have not done the calculation. They do not know which workflows are strategically important. They have not documented the institutional knowledge that would let an AI operate on their behalf. They do not have a measurement baseline that tells them whether what they built is working. Building that foundation is what makes every subsequent bet possible.
For mid-sized organizations that need to accelerate this transformation — specifically how their digital products and customer experiences get rebuilt around AI, from current-state diagnosis to a working operating model — this is the work we do at PH1.
The 2027 Inflection
Three structural shifts are arriving in the next twelve to eighteen months that will change the calculus significantly. Most organizations are not planning for them.
Model Sovereignty
Frontier models will keep improving, but what matters most to most businesses is no longer which model performs best on a benchmark. The question is whether you built dependency on a model that can be restricted, repriced, or shut down by forces outside your control. This is already a compliance and procurement conversation in regulated industries, and it will become one everywhere else. Organizations building infrastructure that can route across models — including older versions, open-source options, and local deployment — are building resilience. Organizations running everything through a single frontier API are building fragility that has not been tested yet.
Token Optimization
CFOs will tighten AI budgets. The organizations already managing this know how to route tasks: which problems need a frontier model, which are handled just as well by something cheaper, how to reduce cost per outcome without reducing outcome quality. Most teams do not have this routing discipline yet. It will become table stakes. The teams that build it now will have a real advantage when the budget pressure arrives — and that pressure is already building in most organizations. We've broken down how model pricing is creating invisible cost liabilities that most finance teams haven't surfaced yet.
The End of Prompting Culture
Prompt engineering, as most teams practice it, is ending as the primary mode of AI deployment. Jensen Huang has been saying this publicly. Boris Cherny, the head of Claude Code at Anthropic, went further — he no longer prompts Claude directly. He builds loops: AI agents that prompt, refine, and test autonomously, without a human in the loop at each step. The most advanced organizations are not building better prompts. They are deploying AI in swarms — multiple agents running in parallel, self-evaluating, self-correcting, operating overnight against criteria the humans defined once.
Reuven Cohen described the shift precisely: "Intelligence is becoming a dynamic, continuously optimized process. Models can allocate more effort to harder problems, while the systems around them evolve to improve outcomes over time." The organizations that do the upfront work of defining their evaluation criteria can configure their AI systems to loop tasks and self-evaluate against those criteria without human supervision at every step. The organizations that have not built that infrastructure will not be able to take advantage of this capability when it becomes standard. The gap will compound.
The Playbook
Four things need to happen for an AI program to survive the shift from adoption to value creation.
1. Be Honest About What Is Actually Happening
Many people inside organizations do not understand why there is so much pressure on AI, or why it feels forced. You cannot mobilize people for a shift they do not understand. The context matters: the businesses that master AI first will consolidate competitive advantage at a pace that mirrors what the internet did to industries in the early 2000s. Say that plainly. The people who need to understand it are not going to get it from a training-day slide deck.
2. Champion What Success Looks Like — and Show It Running
Not a deck about AI. A live workflow that has been rebuilt and is visibly faster, higher quality, or lower cost. People need to see and feel what it means to work somewhere their judgment is the scarce resource, not their capacity. If you cannot show a working example in your own organization, close the distance to one that can.
3. Build Collective Knowledge
Most people are still focused on slightly better outputs from slightly better prompts. The organizations building durable AI capacity have shared tools, shared methods, and institutional expertise — not a collection of individual power users. That may require a Chief AI Officer — CAIO hirings hit a record in Q1 2026, with at least 47 new appointments in the quarter, precisely because no existing role owns this problem end-to-end. It definitely requires someone with the authority to challenge how work is currently structured, not just to train people on tools. Individual adoption without institutional knowledge is the fragile version. It does not compound.
4. Keep the Actual Goal in View
Build better products and services. Solve customer problems more effectively than your competitors. The goal has never been AI adoption — it was always the outcomes AI can enable. Measuring the path instead of the destination is how organizations end up with impressive usage dashboards and nothing defensible to show for them.
Most organizations will start this transition, hit friction at step two or three, and slide back into measuring adoption because it is easier to track and easier to defend in a meeting. The ones that break through are the ones with a leader who ties their own credibility to outcomes, not activity — who treats the measurement infrastructure as non-negotiable rather than a future-quarter initiative. That posture is the difference between the organizations that compound and the ones that announce transformation and then do it again eighteen months later.
The Three Differentiators Most Enterprise AI Programs Miss
The organizations that will pull ahead over the next eighteen months are working on three things that do not get enough coverage.
Non-Technical Leadership Is Now the Differentiator
The technical teams getting the visible wins have convinced many organizations that AI is a technical problem. It was, for a while. The technical limitations were the primary constraint, and engineers were best positioned to work around them. The binding constraint has changed. The models are good enough for most business applications. The differentiator now is orchestration — how context gets structured, how responses get shaped, how the system decides what to do next. Qualitative judgment and domain expertise are the relevant inputs: knowing what a great customer interaction looks like, recognizing when a response is technically correct but strategically wrong. The AI programs that outperform over the next two years will have non-technical leaders at the center. The ones that do not will keep optimizing the wrong layer and wonder why the results stay flat.
The 1% Layer: Where the Next Wave of Gains Actually Sits
Every organization that has run a real AI program for more than eighteen months is discovering the same pattern: the first-wave gains were large and visible, and the second wave is a series of incremental improvements distributed across the system. Three paths to that second wave, based on where the advanced organizations are actually working right now: orchestration and context management, deep analysis of how AI is responding and how users are reacting to that output, and autonomous loops. All three are available now. The organizations not working on them are leaving the next layer of gains on the table while they wait for a model upgrade to solve the problem for them.
Build Real Evaluators — Not Output Checks
The technology required to run autonomous AI workflows is no longer the barrier. The barrier is defining requirements, parameters, and success criteria precisely enough that a system can make adaptive decisions without human supervision at each step. Building a reliable evaluator in a non-engineering context is one of the hardest problems in practical AI deployment — not because the technology is difficult, but because it requires the organization to have a definition of good that is precise enough for a system to check against.
Most organizations do not have that. They have a sense of what good looks like, held in people's heads, that cannot be operationalized. Getting that definition out of people's heads and into a form a system can use is the foundational work. The loops, the autonomous operation, the overnight runs — all of it depends on this. The organizations that build this capability now are the ones that will compound indefinitely. The ones that do not will plateau, and no model upgrade will fix the plateau for them.
Where Does Your Organization Stand?
Before the next budget conversation, before the next restructuring announcement, run this diagnostic on your own program. Five questions that tell you whether your AI investment is building toward something durable or circling the same drain.
- Have you mapped all critical and repetitive workflows? Not catalogued them — documented precisely enough that a system could execute them to your quality standard. If not, you are running AI on undocumented infrastructure. Everything built on it is fragile.
- Have you documented how and why decisions happen, not just what? Most organizations have documented what people do. Almost none have documented why. AI operates on the what. The organizations pulling ahead are feeding it the why.
- Is your AI use stacking value over time? Genuine stacking shows up as measurable improvement in output quality month over month — not just time saved. If outputs are not meaningfully better than three months ago, you are not stacking.
- Do you have a source of truth any person or agent can use to understand how another team works? If institutional knowledge lives in people's heads, your AI program's ceiling is the knowledge of the individual using it at that moment.
- Do you have leaders who make AI wins — and failures — visible? 79% of managers have not demonstrated AI use to their own team in the past month. That signals it is optional. Culture follows what leadership makes visible.
If you answered no to more than two of these, your AI program is not a value creation program. It is an adoption program with a value creation label on it.
For organizations that want a structured outside diagnosis of where their AI investment is stalling — and a roadmap to close the gap — AI Value Acceleration has built the measurement frameworks and operational playbooks for exactly this problem.
The adoption phase of AI is over, and the organizations that treated it as the destination are about to find out what they built does not hold. The organizations that treated adoption as a beginning — and did the harder work of building documented workflows, explicit quality criteria, and measurement tied to real business outcomes — are positioned for what comes next. The gap between those two groups is already large and is widening every quarter.
About the author: Arpy Dragffy is an AI product strategist and the founder of PH1, a consultancy that helps organizations improve the measurable success of their AI products and digital experiences. He co-hosts the Product Impact Podcast with Brittany Hobbs and writes on AI strategy, enterprise product development, and the future of work. For enterprise AI value creation diagnostics and frameworks, visit AI Value Acceleration.
How helpful was this article?
Share this article
Latest Episodes ›
All episodes
15. Playbook for Increasing AI Adoption & Value Creation

14: AI Adoption is the Problem Everyone is Desperate to Solve — Dr. Molly Sands, Atlassian
![13. Why Managing AI Agents Is More Like Supervising Labor Than Using a Tool [Jonathan Su, Procurify]](https://d3t3ozftmdmh3i.cloudfront.net/staging/podcast_uploaded_episode/40697999/40697999-1780762138875-86f6d02d9c458.jpg)
13. Why Managing AI Agents Is More Like Supervising Labor Than Using a Tool [Jonathan Su, Procurify]

The Product Team's Claude Code Playbook: 20 Commands Worth Learning This Sprint
New Report Says You're Wasting More Time Botsitting Than Getting Value from AI

Eight Frameworks for Measuring AI ROI — And How to Use Each One

The UX Researcher's Guide to Claude, Claude Cowork, and Claude Code

WTF is an AI-native org anyways? Let's compare Airbnb & Meta's opposing plans.

The Free Ride Is Over: AI Economics Is Now Your Most Important Strategy Decision
Product Impact Newsletter
AI product strategy delivered weekly. Free.